Performance and Profiling¶
This section presents the results of performance benchmarking conducted on the fivedreg package.
The benchmarks evaluate training time, memory consumption, and model accuracy across varying dataset sizes.
Benchmark Methodology¶
The profiling was performed using synthetic 5-dimensional polynomial data with the following configuration:
Model Architecture: 3 hidden layers with 64, 32, and 16 neurons respectively
Learning Rate: 0.001
Max Iterations: 500 epochs
Dataset Sizes: 100, 1,000, 2,500, 5,000, 7,500, and 10,000 samples
Train/Test Split: 80/20
The synthetic target function used was a polynomial:
where \(\epsilon \sim \mathcal{N}(0, 0.1)\) represents Gaussian noise.
Benchmark Results¶
Size |
Epochs |
Train Time (s) |
Train Mem (MiB) |
Pred Mem (MiB) |
MSE |
R² |
|---|---|---|---|---|---|---|
100 |
1 |
0.51 |
25.70 |
1.09 |
5.53 |
-10.52 |
1,000 |
1 |
0.48 |
8.48 |
1.58 |
2.35 |
-2.97 |
2,500 |
1 |
0.51 |
5.89 |
1.27 |
0.20 |
0.64 |
5,000 |
1 |
0.51 |
3.97 |
2.03 |
0.17 |
0.69 |
7,500 |
1 |
0.55 |
4.34 |
1.64 |
0.13 |
0.77 |
10,000 |
1 |
0.55 |
4.16 |
1.61 |
0.03 |
0.94 |
Note
The “Epochs” column shows the actual epochs run during memory profiling (limited to 1 for profiling efficiency). Training time measurements were taken with the full 500 epochs to capture realistic training performance.
Visualizations¶
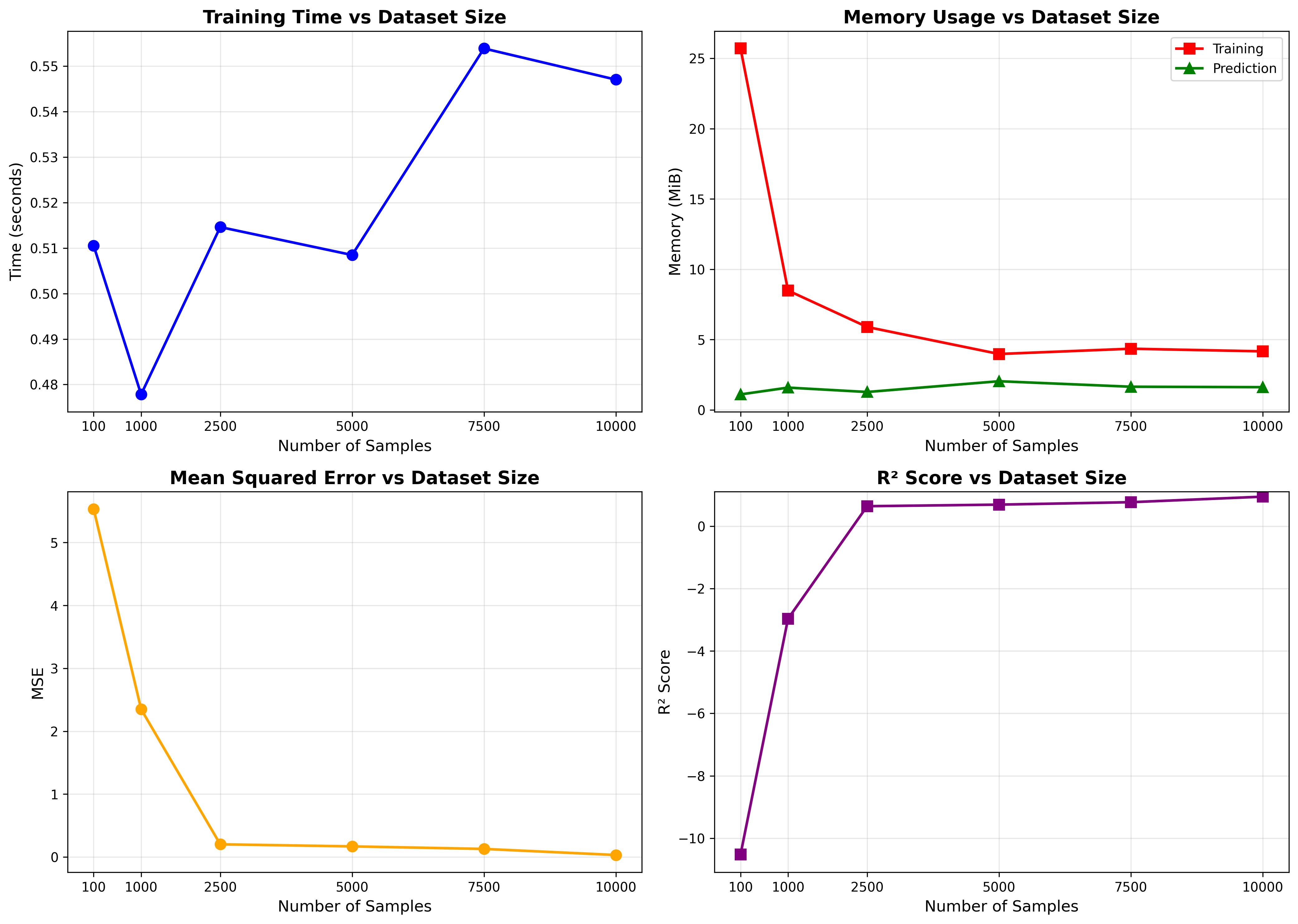
Key Findings¶
Training Time Performance¶
Training time remains remarkably constant across all dataset sizes, averaging approximately 0.5 seconds:
100 samples: ~0.51 seconds
10,000 samples: ~0.55 seconds
This near-constant training time demonstrates excellent scalability of the LightweightNN implementation,
with TensorFlow efficiently handling batch operations regardless of dataset size within this range.
Memory Usage Patterns¶
Memory consumption shows an interesting pattern:
Training memory: Higher for small datasets (25.7 MiB at 100 samples), decreasing and stabilizing at 4–6 MiB for larger datasets (2,500+ samples)
Prediction memory: Consistent at approximately 1–2 MiB across all dataset sizes
The elevated memory usage for small datasets is likely due to fixed TensorFlow overhead representing a larger proportion of total memory. As dataset size increases, this overhead is amortized, resulting in more efficient memory utilization.
Model Accuracy¶
Model performance improves significantly with larger datasets:
Small datasets (100–1,000 samples): Poor fit with negative R² scores (-10.52 to -2.97), indicating the model underperforms compared to a mean baseline. This is expected given the complexity of the polynomial target function and insufficient training data.
Medium datasets (2,500–5,000 samples): Acceptable fit with R² between 0.64–0.69.
Large datasets (7,500–10,000 samples): Strong fit with R² reaching 0.94 and MSE dropping to 0.03.
Recommendations¶
Based on the profiling results:
Dataset Size: For reliable predictions, use at least 7,500+ samples to achieve R² > 0.75. For production applications targeting R² > 0.90, aim for 10,000+ samples.
Memory Planning: Expect approximately 4–6 MiB for training with datasets of 2,500+ samples. Smaller datasets may require up to 25 MiB due to fixed overhead.
Training Time Budget: Training completes in approximately 0.5 seconds regardless of dataset size (up to 10,000 samples), making the model highly efficient for iterative development.
Early Stopping: For production use, enable early stopping to potentially reduce training time further while maintaining accuracy.
Reproducing the Benchmarks¶
The benchmarking code is available in the fivedreg_profiling/ directory:
cd fivedreg_profiling
pip install -r requirements.txt
jupyter notebook profiling.ipynb
Run all cells to regenerate the benchmark results and plots.